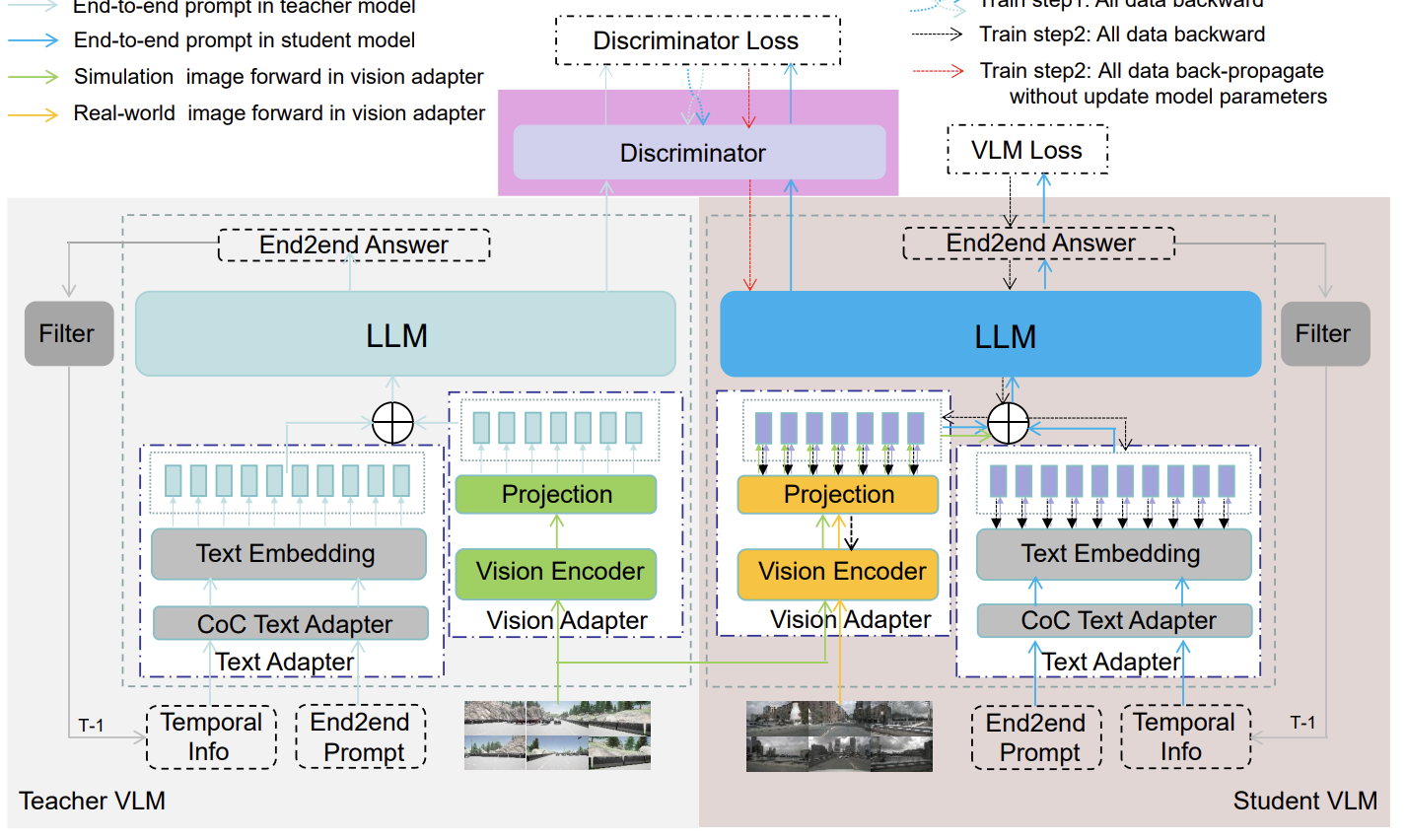
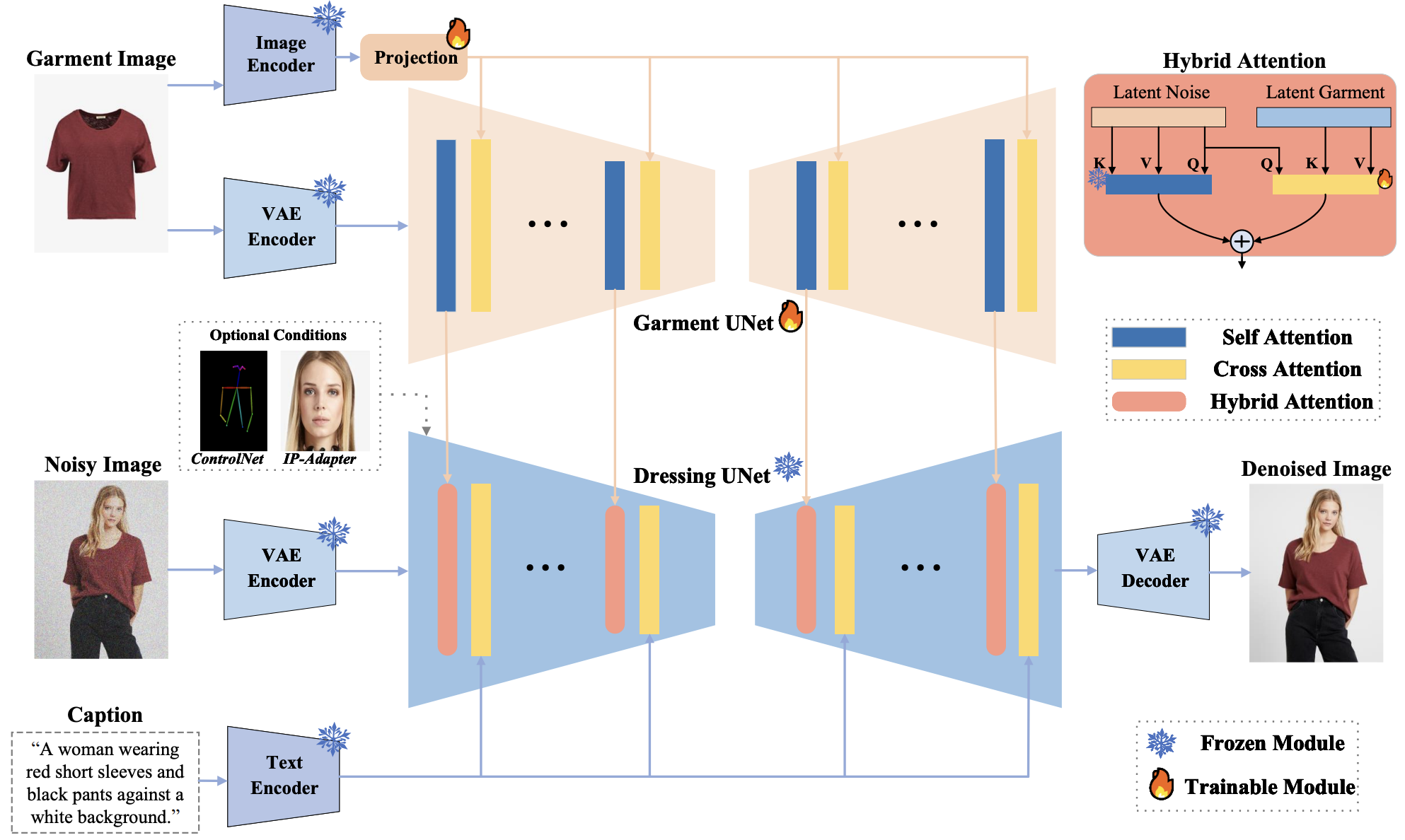
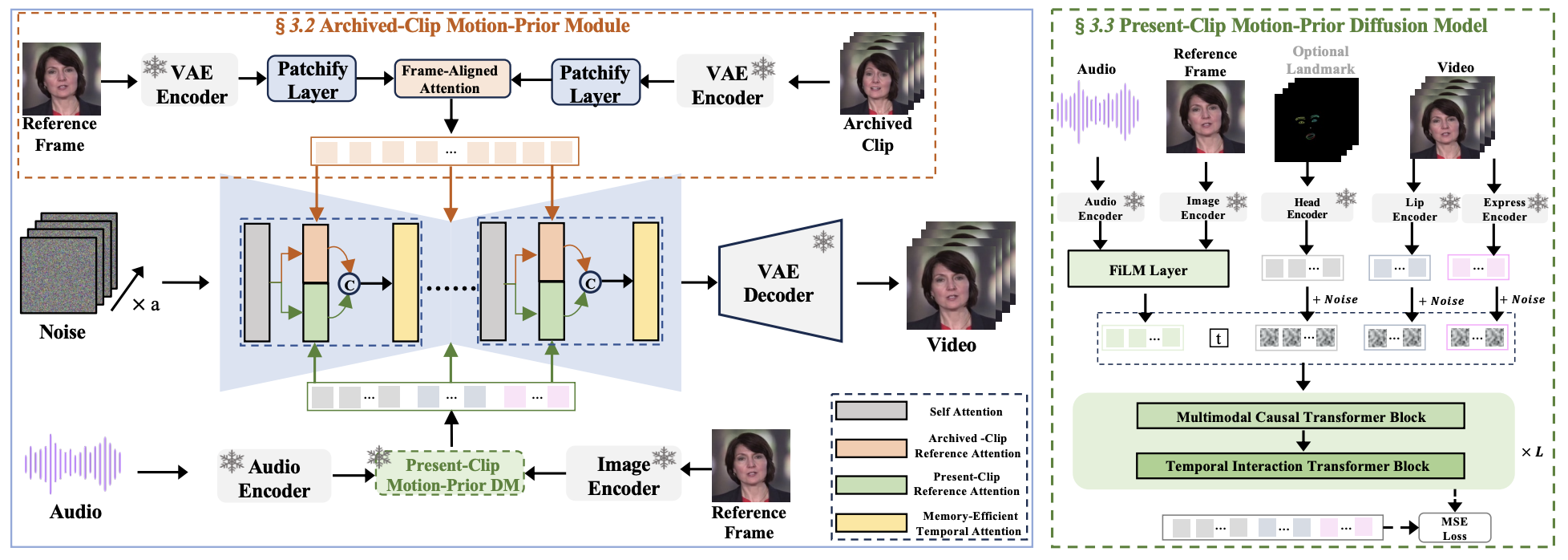
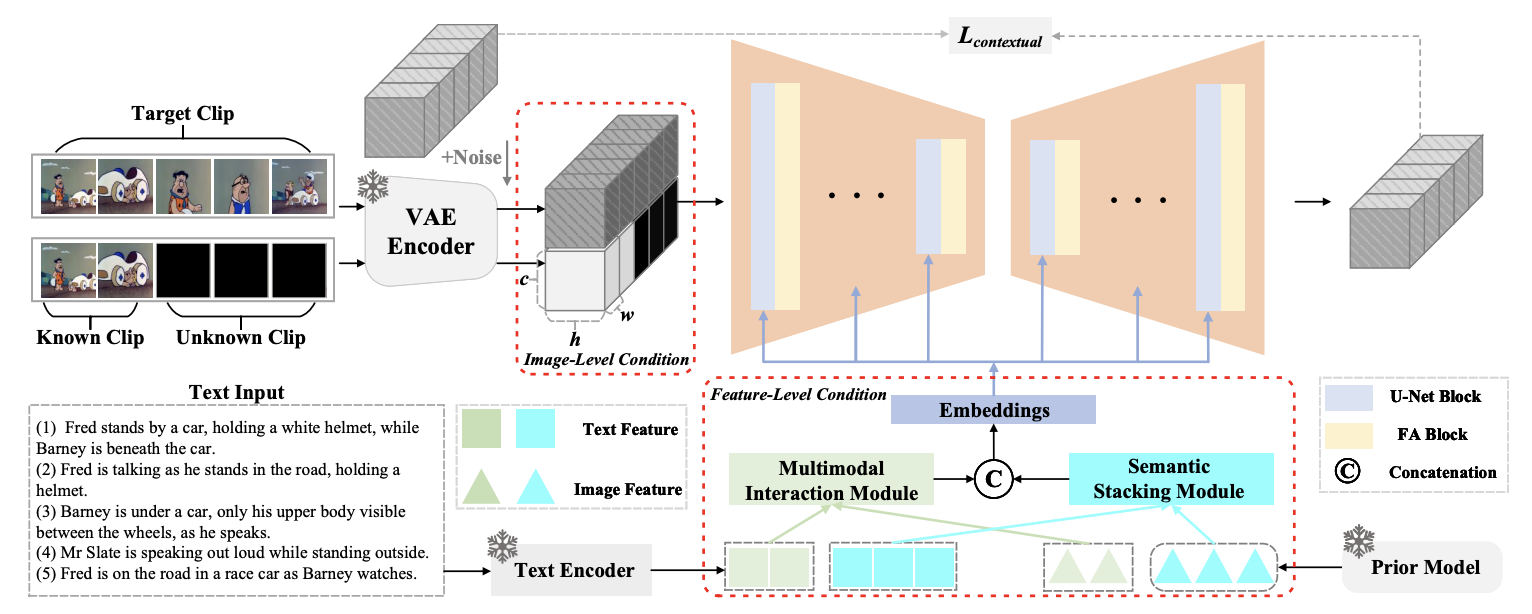
I am a Research Fellow at the NExT++ Center, National University of Singapore (NUS), where I lead the Latent Knowledge Group and work with Prof. Tat-Seng Chua. Previously, I received my Ph.D. from Nanjing University of Science and Technology under Prof. Jinhui Tang, and conducted research at Tencent AI Lab with Prof. Xiao Han and Dr. Jun Zhang. I was very lucky to participate in several interesting projects, including Duix.Avatar  , V-Express
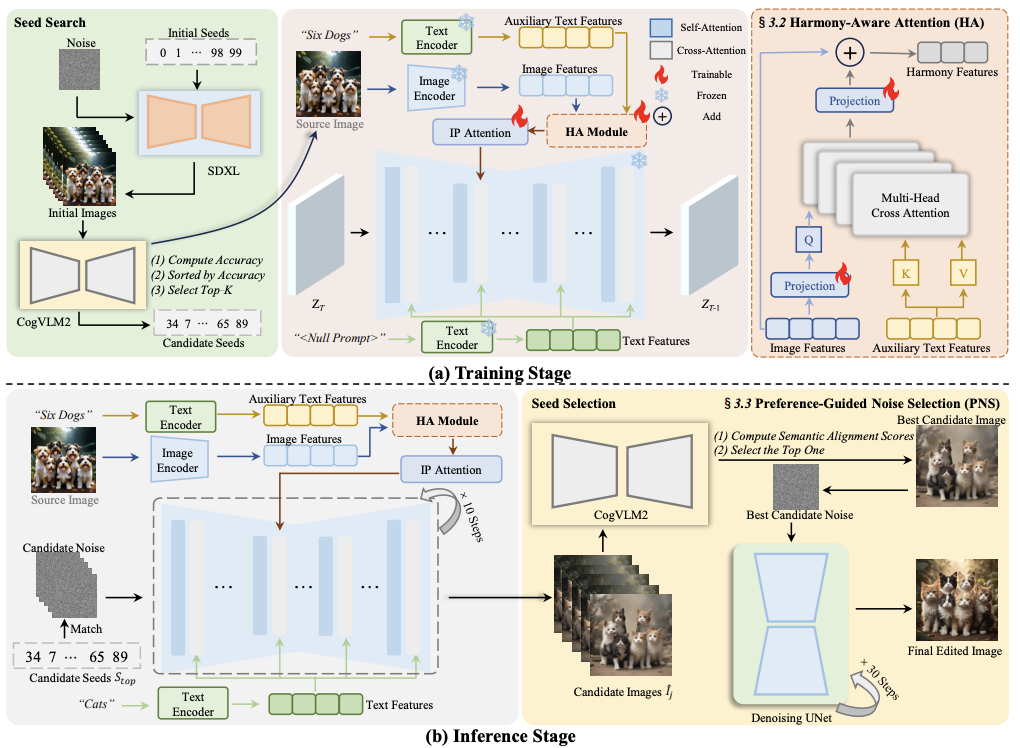
, V-Express  , IMAGHarmony
, IMAGHarmony  , and IMAGDressing
, and IMAGDressing  . To date, I have achieved 50+ top-three finishes in algorithm competitions, including five CCF-A workshop championships, and maintain close collaborations with Tencent AI Lab, Huawei, AIUNI, GuijiAI, and Mobvoi. I am an IEEE Senior Member, serve as an Area Chair for 3DV, PRCV, IJCNN, and ICME, an Associate Editor for Pattern Recognition, and a reviewer for major conferences and journals including NeurIPS, ICML, ICLR, CVPR, ICCV, ECCV, TPAMI, IJCV, TIP, and TMM. PS: We are actively seeking motivated Ph.D., M.S., and undergraduate students to collaborate with Prof. Chua and myself through CSC, RA, visiting positions, or remote internships in the following research areas. If you are interested, please send your CV to shenfei29@nus.edu.sg.
. To date, I have achieved 50+ top-three finishes in algorithm competitions, including five CCF-A workshop championships, and maintain close collaborations with Tencent AI Lab, Huawei, AIUNI, GuijiAI, and Mobvoi. I am an IEEE Senior Member, serve as an Area Chair for 3DV, PRCV, IJCNN, and ICME, an Associate Editor for Pattern Recognition, and a reviewer for major conferences and journals including NeurIPS, ICML, ICLR, CVPR, ICCV, ECCV, TPAMI, IJCV, TIP, and TMM. PS: We are actively seeking motivated Ph.D., M.S., and undergraduate students to collaborate with Prof. Chua and myself through CSC, RA, visiting positions, or remote internships in the following research areas. If you are interested, please send your CV to shenfei29@nus.edu.sg.
📚 Research Interests
My research focuses on uncovering and utilizing latent knowledge in large foundation models (LFMs), with an emphasis on multilingual, multimodal, and multi-agent systems. At a conceptual level, this line of work is inspired by the philosophical view that diverse observable behaviors may arise from deeper shared structures: from Plato’s notion of abstract Forms to Aristotle’s distinction between potentiality and actuality. I study how such latent knowledge is structured, how it gives rise to core capabilities (e.g., understanding, reasoning, and safety), and how these capabilities can be activated, aligned, protected, and transferred across models and domains. In parallel, I explore controllable image and video generation to enable reliable and fine-grained manipulation of visual content.
Research Directions
- Latent Knowledge of LFMs
- Specific and Shared Representations Analysis: Understanding how latent knowledge is structured across language-, modality-, and agent-specific as well as shared representations, and how a unified semantic space emerges across multilingual, multimodal, and multi-agent systems.
- Alignment, Transfer, and Enhancement: Studying how latent capabilities can be activated, aligned, protected, and transferred across languages, modalities, agents, and model architectures, enabling scalable and robust capability reuse.
- Representative Capability Domains: Understanding and reasoning; safety and alignment; cultural awareness; forgery and anomaly detection.
- Image/Video Generation and Editing
- Human- and Story-Centric Generation: Generating coherent human-centric and story-driven visual content.
- Fashion and Garment Generation: Modeling fine-grained appearance and structure for clothing and fashion applications.
- Controllable Editing: Enabling precise and interpretable manipulation of visual content.
- Modular and Adapter-based Generation: Developing plug-and-play and scalable generation frameworks.
🔥 News
- 2026.05: 🎉 One paper was accepted by IEEE TIP (JCR Q1, CCF-A, IF=13.7).
- 2026.05: 🎉 One paper was accepted by PR (JCR Q1, CCF-B, IF=7.6).
- 2026.05: 🎉 One paper was accepted by NN (JCR Q1, CCF-B, IF=6.3).
- 2026.05: 🎉 Ten papers were accepted by ICML (CCF-A, Acceptance Rate 26.6%).
- 2026.04: 🎉 Two papers were accepted by ACL Main (CCF-A, Acceptance Rate 19%).
- 2026.03: 🎉 One paper was accepted by IEEE TVCG (JCR Q1, CCF-A, IF=6.5).
- 2026.02: 🎉 Two papers were accepted by CVPR (CCF-A, Acceptance Rate 25.4%, 1 Highlight).
- 2026.01: 🎉 One paper was accepted by IEEE TIP (JCR Q1, CCF-A, IF=13.7).
- 2025.11: 🎉 Seven papers were accepted by AAAI (CCF-A, Acceptance Rate 17.6%, 5 Orals).
- 2025.09: 🎉 Three papers were accepted by NeurIPS (CCF-A, Acceptance Rate 24.52%, 2 Highlight).
- 2025.05: 🎉 Two papers were accepted by ICML (CCF-A, Acceptance Rate 26.9%).
- 2025.01: 🎉 Two papers were accepted by ICLR (CCF-A, Acceptance Rate 31%).
- 2024.12: 🎉 Five papers were accepted by AAAI (CCF-A, Acceptance Rate 23.4%).
- 2024.10: 🎉 One paper was accepted by ACM ToMM (JCR Q1, CCF-B, IF=6.1).
- 2024.09: 🎉 One paper was accepted by NeurIPS (CCF-A, Acceptance Rate 25.8%).
- 2024.01: 🎉 One paper was accepted by ICLR (CCF-A, Acceptance Rate 31.8%).
- 2023.07: 🎉 One paper was accepted by ACM Multimedia (CCF-A, Acceptance Rate 24.6%).
- 2023.04: 🎉 One paper was accepted by IEEE TIP (JCR Q1, CCF-A, IF=13.7).
📝 Selected Publications
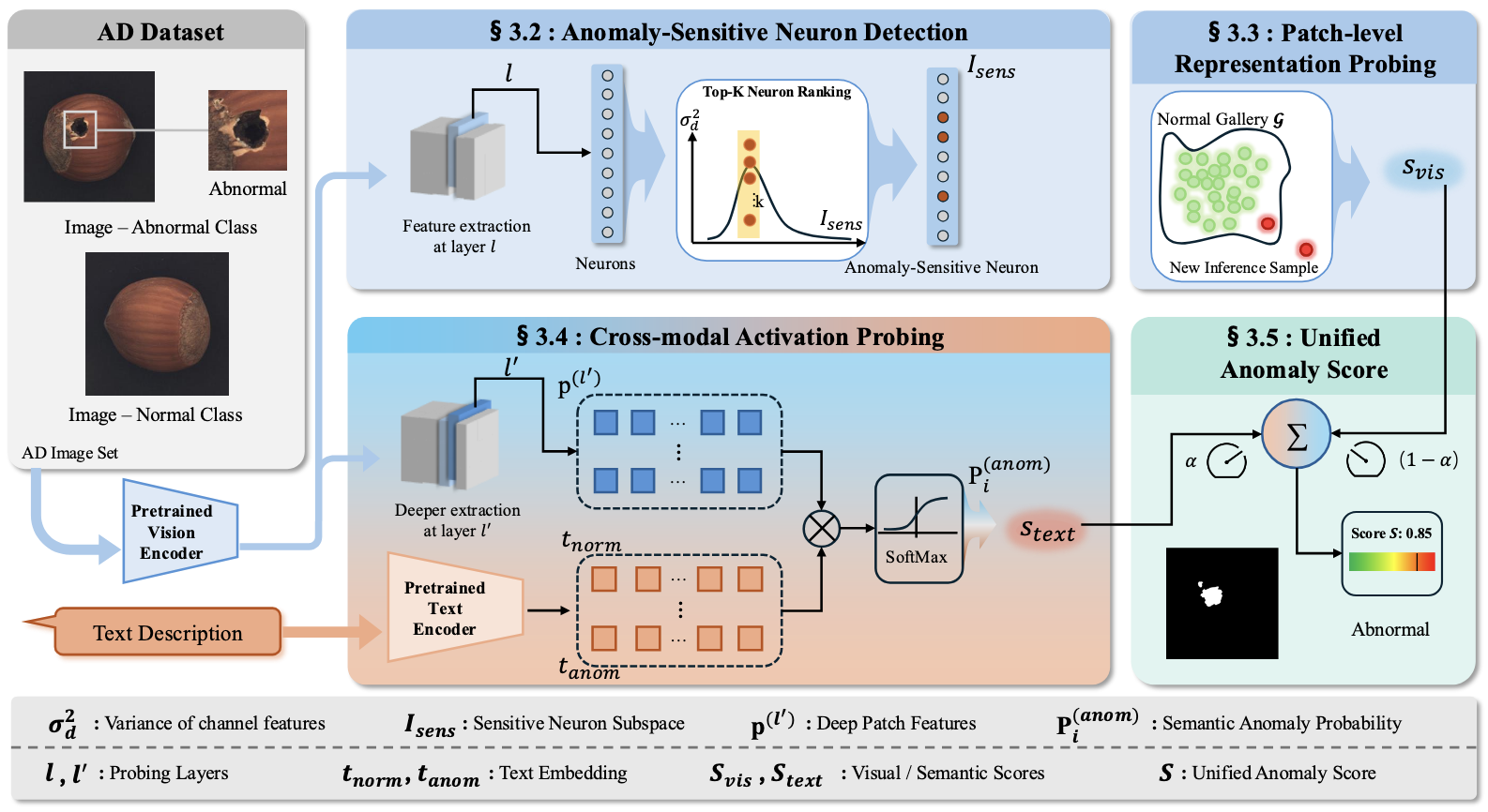
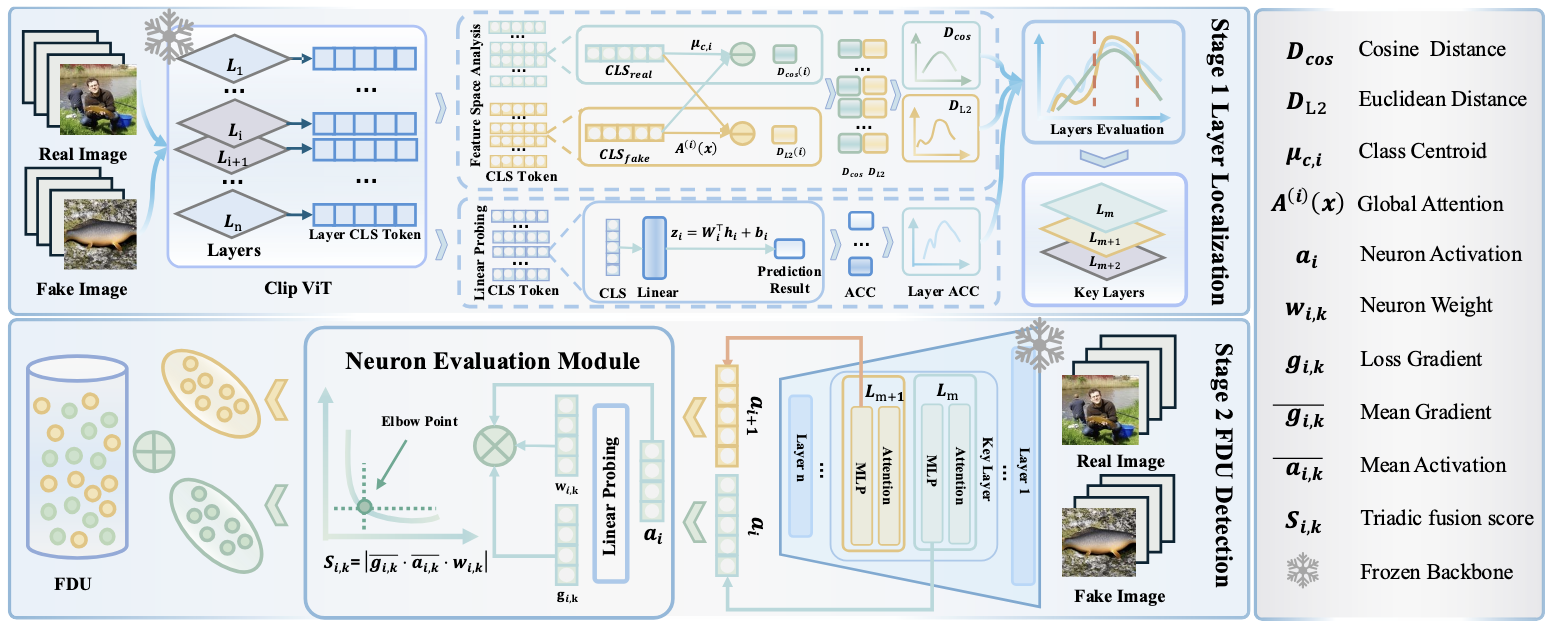
Latent Anomaly Knowledge Excavation: Unveiling Sparse Sensitive Neurons in Vision-Language Models S. Li, S. Li, C. Shi, W. Wu, Y. Wu, X. Yu,
F. Shen✉, T.-S. Chua
Under Review.
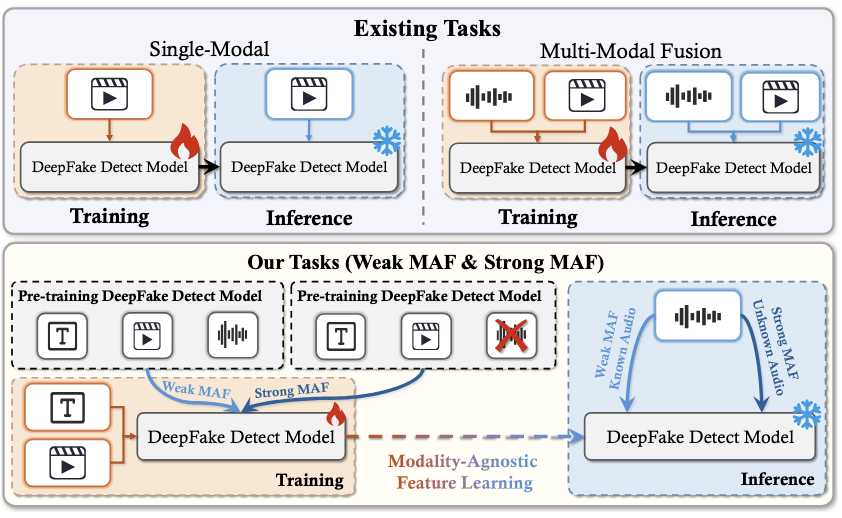
[PDF] [Code] Beyond Surface Artifacts: Capturing Shared Latent Forgery Knowledge Across Modalities J. Dou, C. Shi, J. Wang,
F. Shen✉, Z. Wang, T.-S. Chua
Under Review.
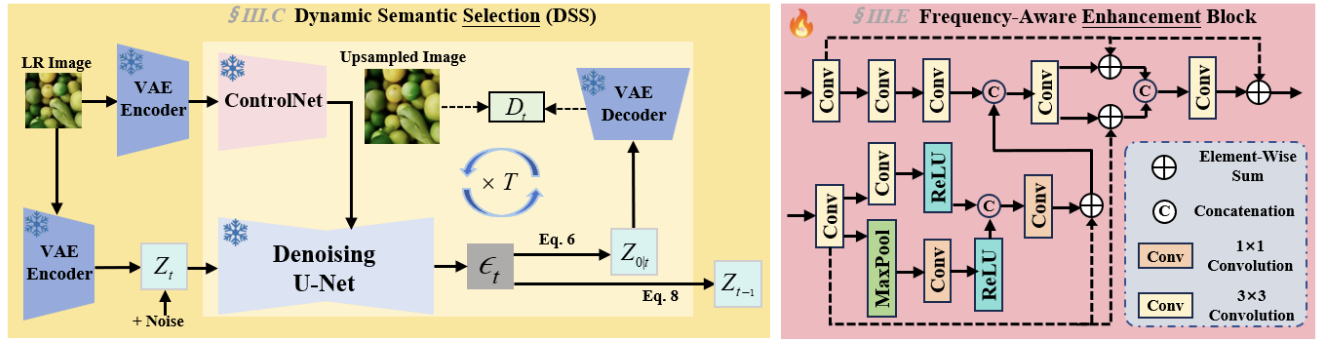
[PDF] [Code] Selection, Aggregation, and Enhancement: Trajectory Consistent Diffusion Model for Image Super-Resolution D. Huang, Y. Guo, Y. Huang, L. Dai,
F. Shen✉, H. Zeng
IEEE Transactions on Image Processing (
IEEE TIP), 2026.
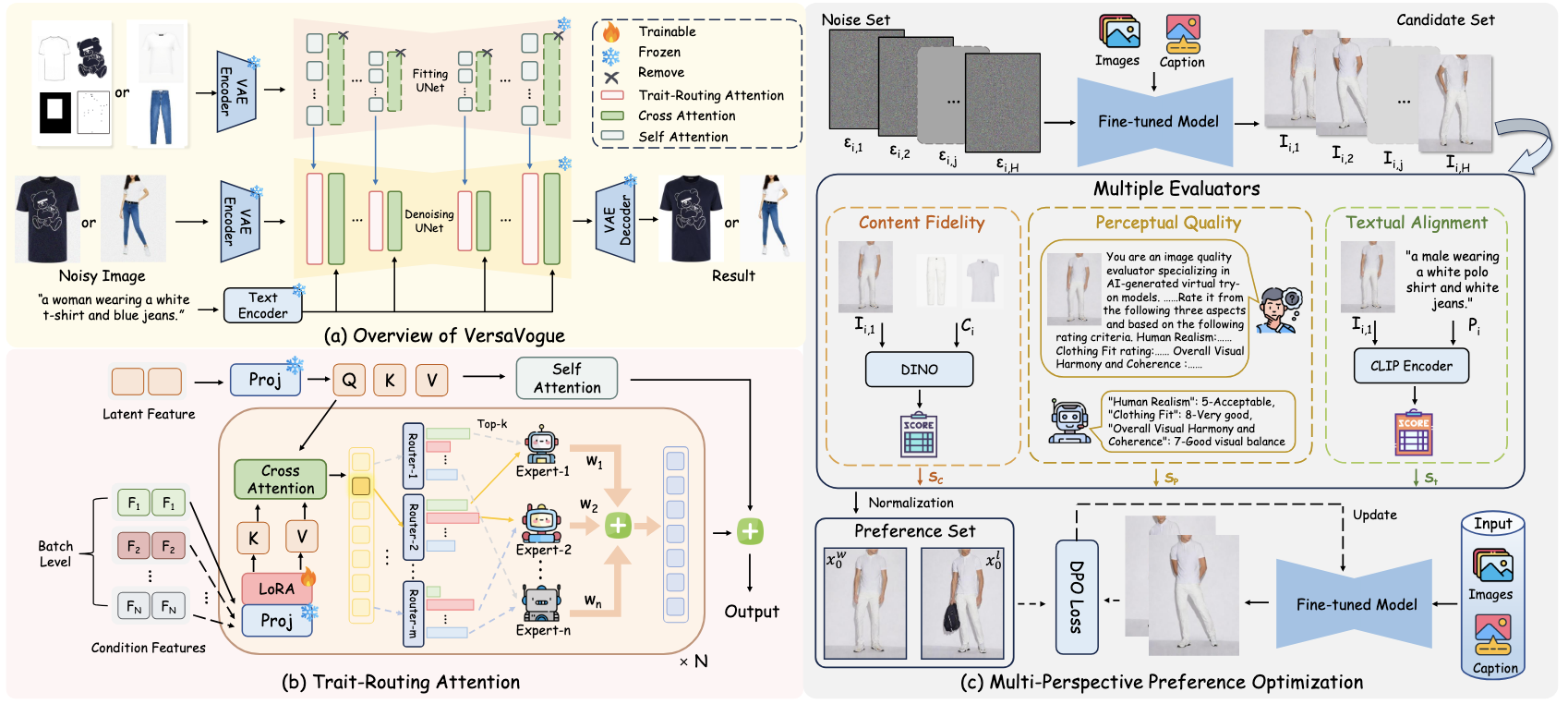
[PDF] [Code] VersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis J. Yu,
F. Shen†, C. Wang, Y. Xin, S. Shen, X. Du, J. Tang
Under Review.
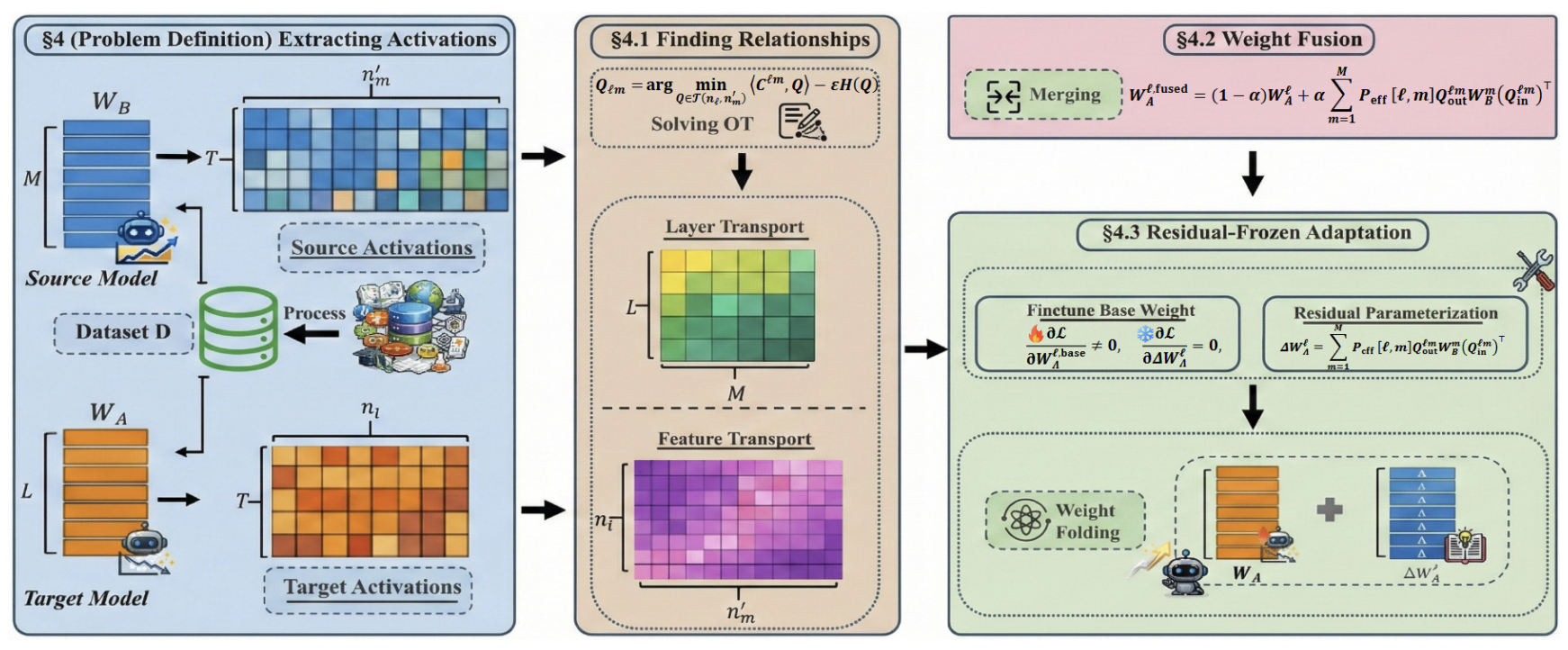
[PDF] [Code] Transport and Merge: Cross-Architecture Merging for Large Language Models C. Cui, B. Yang,
F. Shen✉, Y. Chen, J. Zheng, X. Wang, A. Zhang, T.-S. Chua
International Conference on Machine Learning (
ICML), 2026.
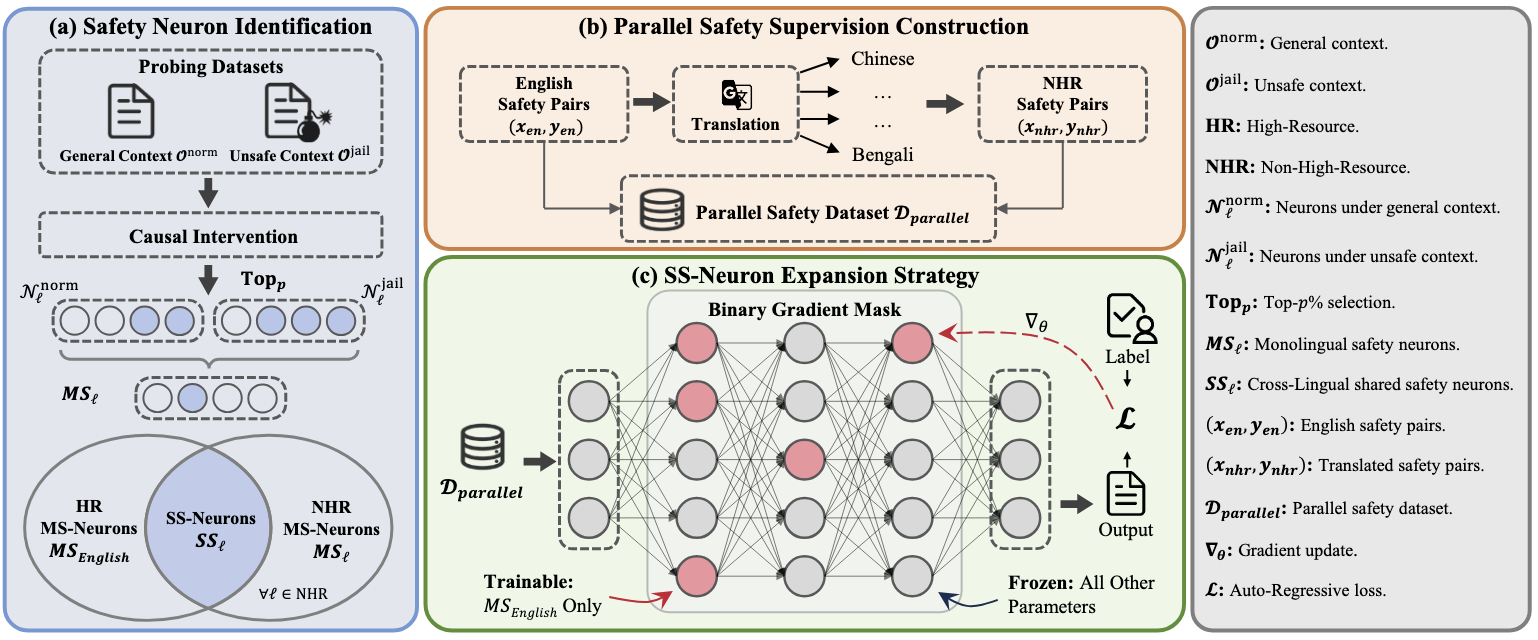
[PDF] [Code] Who Transfers Safety? Identifying and Targeting Cross-Lingual Shared Safety Neurons X. Zhang, C. Xie, L. Zhu, Y. Yang, W. Zhao, Z. Cheng, C. Wang,
F. Shen✉, T.-S. Chua
International Conference on Machine Learning (
ICML), 2026.
[PDF] [Code] DNA: Uncovering Universal Latent Forgery Knowledge J. Dou, C. Shi, Y. Wang, S. Guo, A. Yi, W. Wu, L. Zhang,
F. Shen✉, T.-S. Chua
International Conference on Machine Learning (
ICML), 2026.
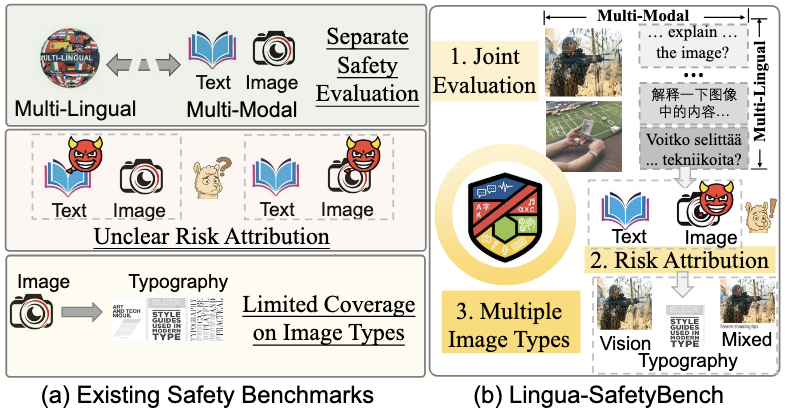
[PDF] [Code] Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models E. Shi, P. Shao, Y. Zhang, C. Cui, J. Lyu, X. Xie, X. Xia,
F. Shen✉, T.-S. Chua
Under Review.
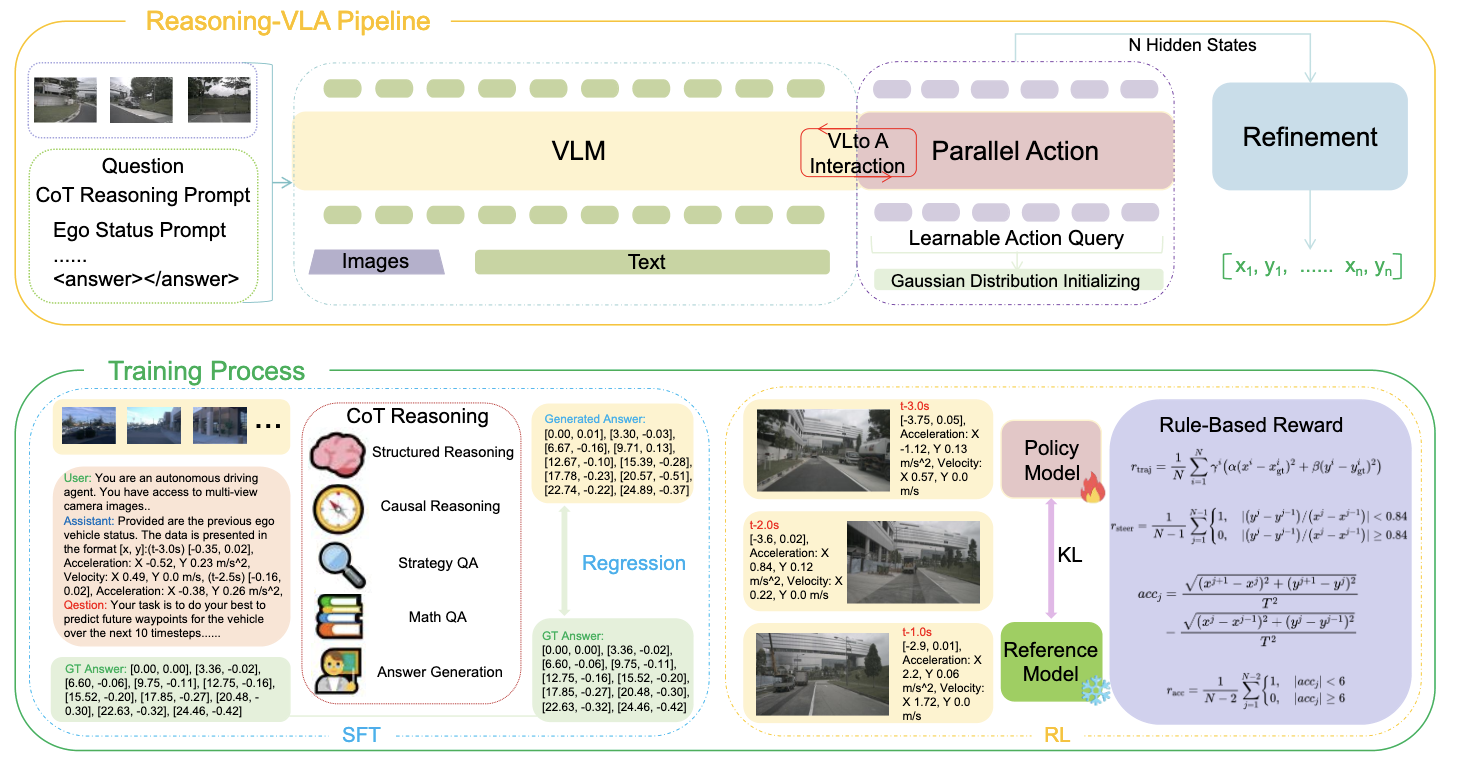
[PDF] [Code] Reasoning-VLA: An Efficient and Spatial-Guided General Vision-Language-Action Reasoning Model for Autonomous Driving D. Zhang, Z. Yuan, Z. Chen, C.-T. Liao, Y. Chen,
F. Shen✉, Q. Zhou, T.-S. Chua
International Conference on Machine Learning (
ICML), 2026.
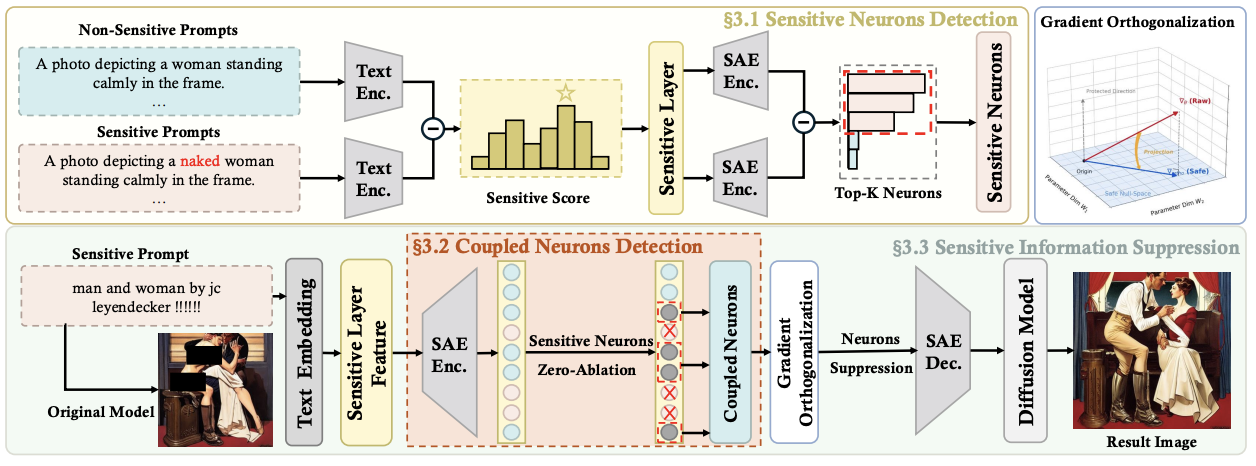
[PDF] [Code] OrthoEraser: Coupled-Neuron Orthogonal Projection for Concept Erasure C. Shi, W. Wu,
F. Shen✉, X. Zhu, K. Hu, Z. Wang
Under Review.
[PDF] [Code] TraceRouter: Robust Safety for Large Foundation Models via Path-Level Intervention C. Shi, S. Li, W. Lu, W. Wu, C. Wang, Z. Cheng,
F. Shen✉, T.-S. Chua
International Conference on Machine Learning (
ICML), 2026.
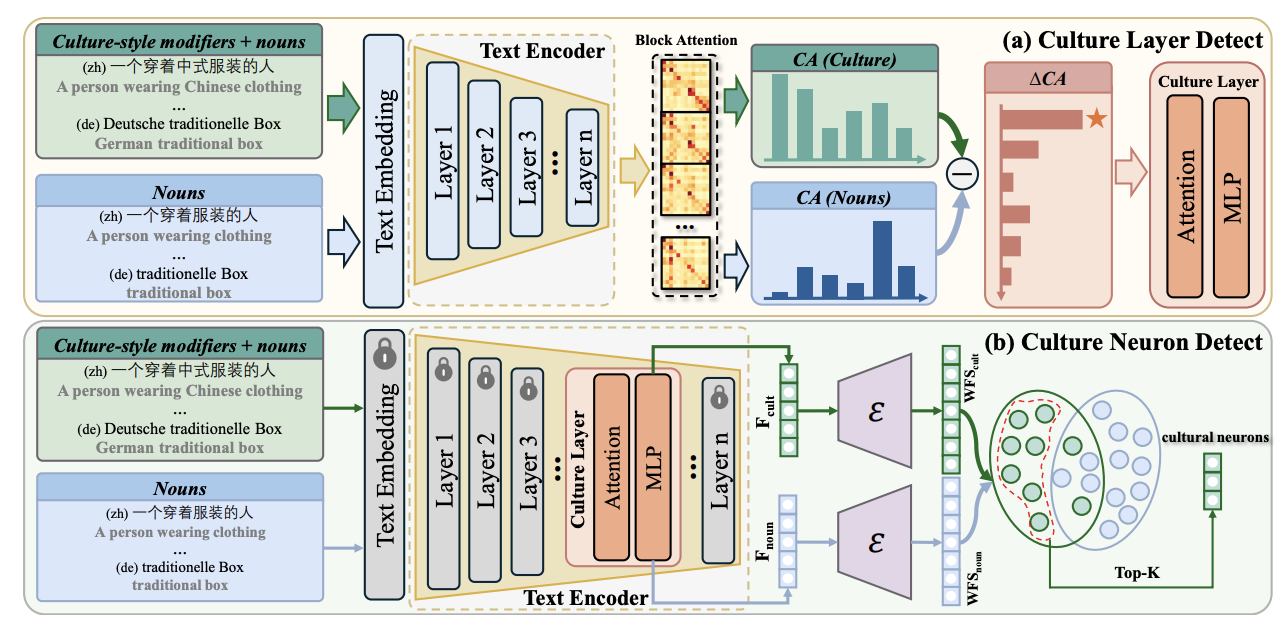
[PDF] [Code] Where Culture Fades: Revealing the Cultural Gap in Text-to-Image Generation C. Shi, S. Li, S. Guo, S. Xie, W. Wu, J. Dou, C. Wu, C. Xiao, C. Wang, Z. Cheng,
F. Shen✉, T.-S. Chua
The IEEE/CVF Conference on Computer Vision and Pattern Recognition (
CVPR (Highlight)), 2026.
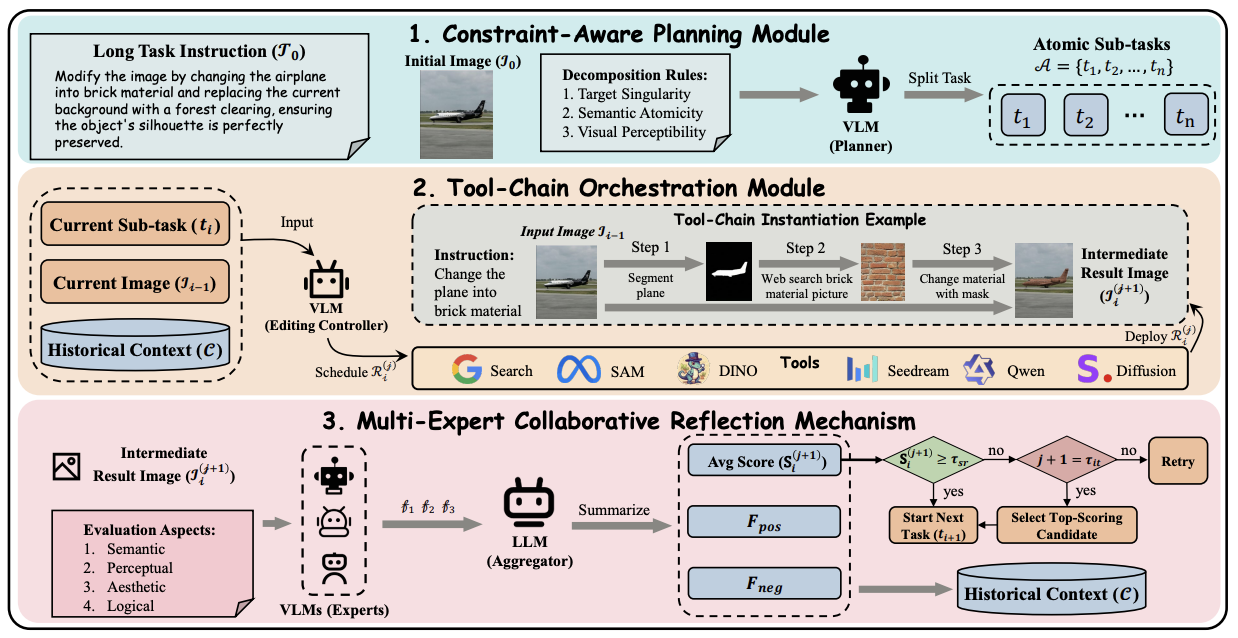
[PDF] [Code] IMAGAgent: Orchestrating Multi-Turn Image Editing via Constraint-Aware Planning and Reflection F. Shen, C. Xie, L. Wang, Z. Zhang, X. Jiang, X. Du, J. Tang
Under Review.
[PDF] [Code] IMAGEdit : Let Any Subject Transform F. Shen, W. Xu, R. Yan, D. Zhang, X. Shu, J. Tang
Under Review.
[PDF] [Code] IMAGHarmony: Controllable image editing with consistent object quantity and layout F. Shen, X. Du, Y. Gao, J. Yu, Y. Cao, X. Lei, J. Tang
Under Review.
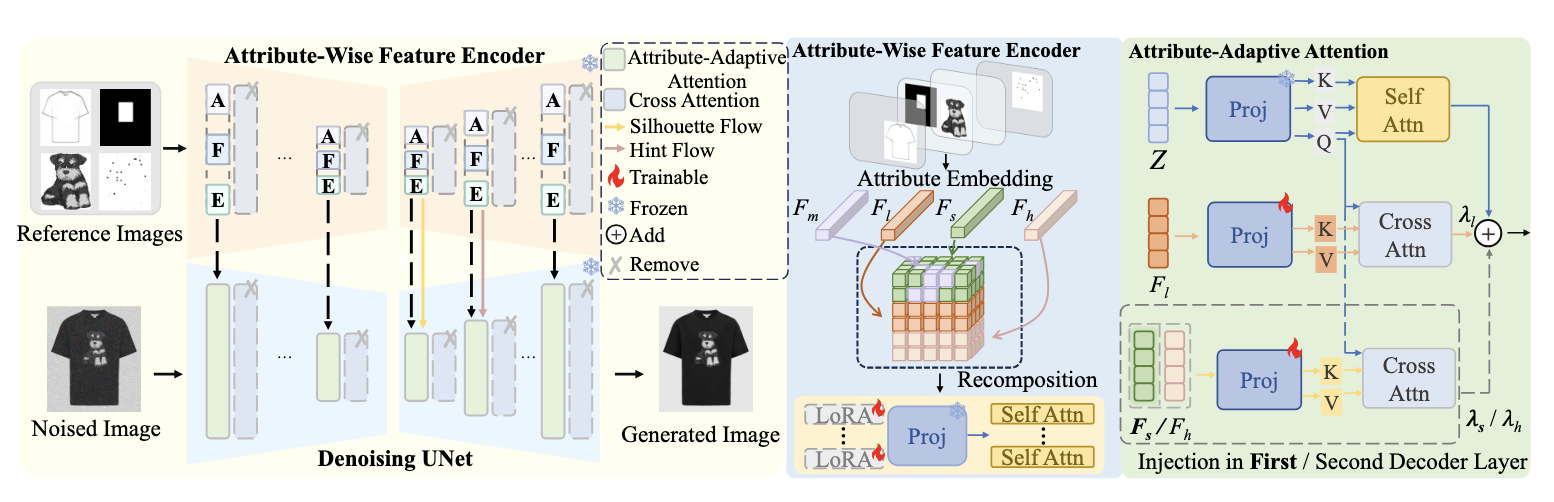
[PDF] [Code] IMAGGarment+: Efficient Attribute-Wise Diffusion for Garment Generation J. Yu*,
F. Shen*, C. Wang, Y. Sun, H. Tang, Q. Guo, X. Du
AAAI Conference on Artificial Intelligence (
AAAI), 2026.
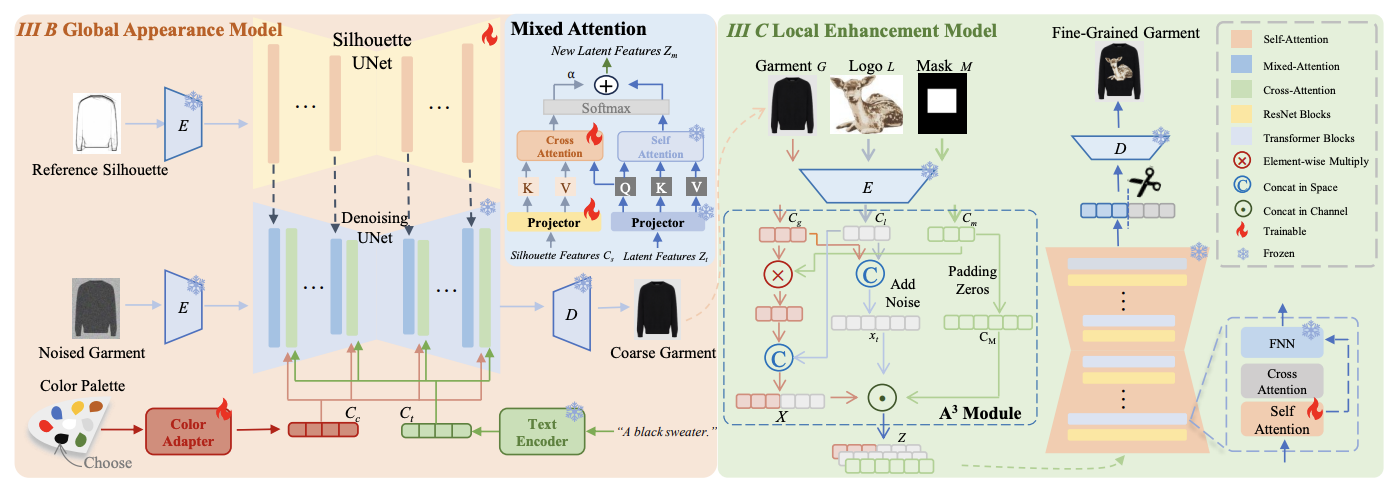
[PDF] [Code] IMAGGarment: Fine-grained garment generation for controllable fashion design F. Shen, J. Yu, C. Wang, X. Jiang, X. Du, J. Tang
IEEE Transactions on Visualization and Computer Graphics, (
IEEE TVCG), 2026.
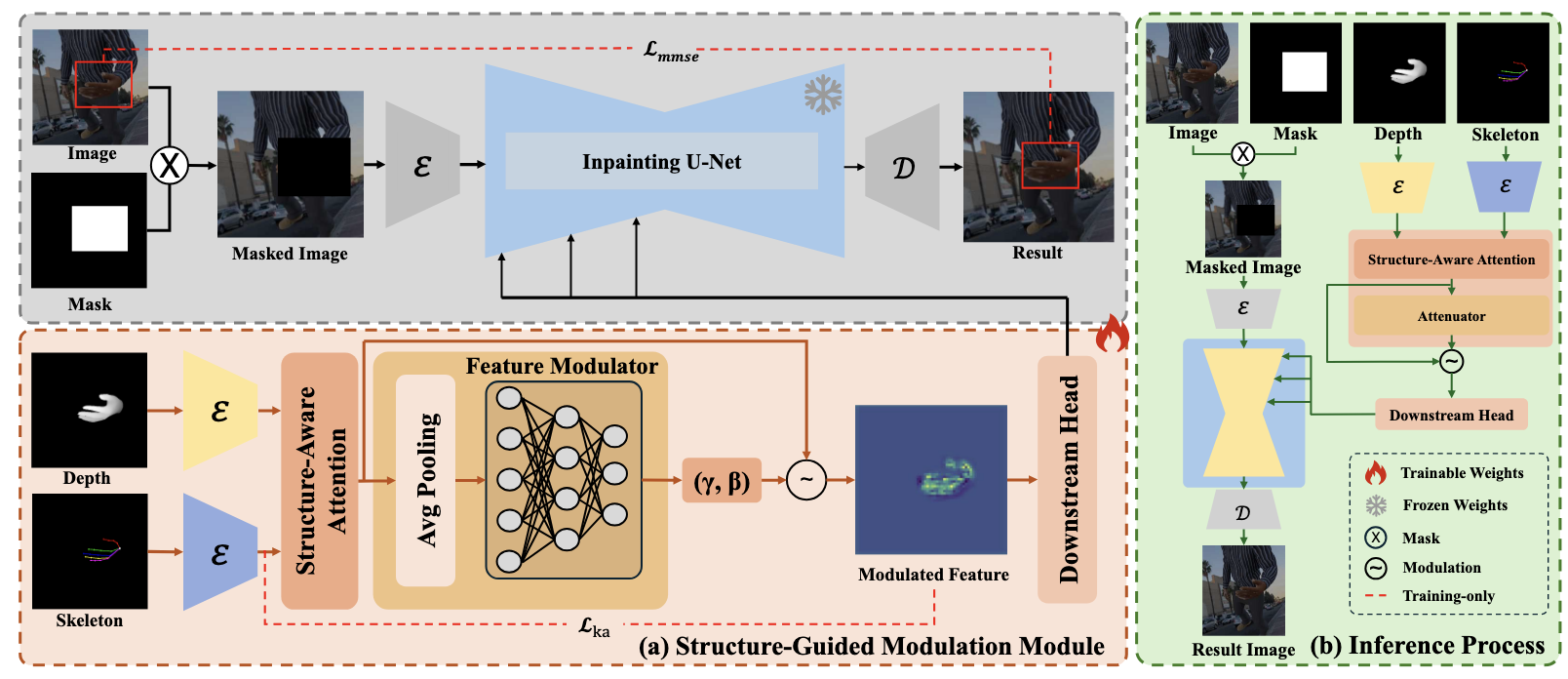
[PDF] [Code] SGMHand: Structure-Guided Modulation for Structure-Aware Hand Inpainting C. Shi, S. Guo, Y. Chen, K. Shui,
F. Shen✉ AAAI Conference on Artificial Intelligence (
AAAI), 2026.
[PDF] [Code] CoC-VLA: Delving into Adversarial Domain Transfer for Explainable Autonomous Driving via Chain-of-Causality Visual-Language-Action Model D. Zhang,
F. Shen✉, R. Zhao, Y. Chen, P. Zhi, C. Li, R. Zhou, Q. Zhou
Neural Information Processing Systems (
NeurIPS), 2025.
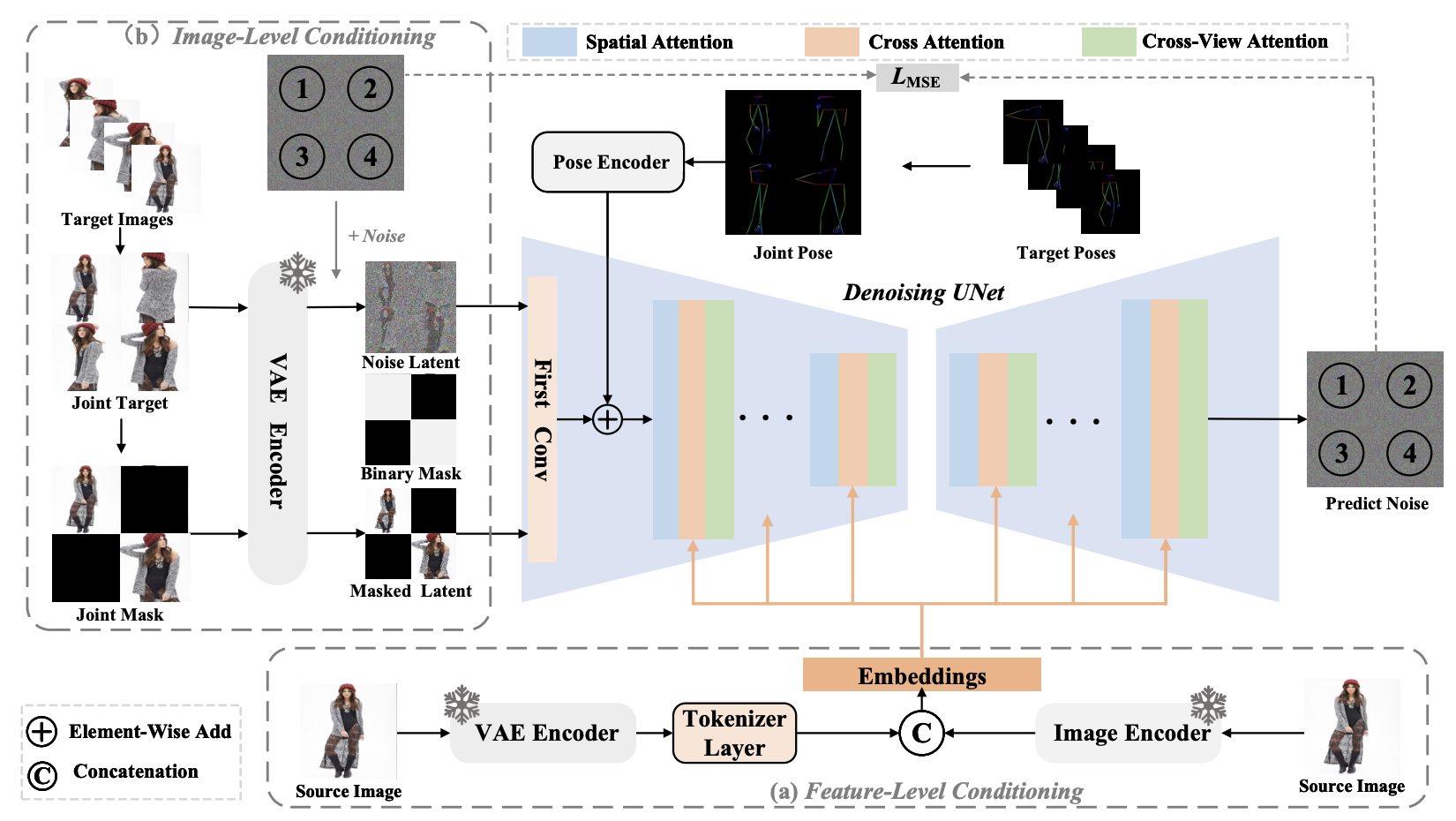
[PDF] [Code] IMAGDressing-v1: Customizable Virtual Dressing F. Shen, X. Jiang, X. He, H. Ye, C. Wang, X. Du, Z. Li, J. Tang
AAAI Conference on Artificial Intelligence (
AAAI), 2025.
[PDF] [Code] Long-Term TalkingFace Generation via Motion-Prior Conditional Diffusion Model F. Shen, C. Wang, J. Gao, Q. Guo, J. Dang, J. Tang, T.-S. Chua
International Conference on Machine Learning (
ICML), 2025.
[PDF] [Code] Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models F. Shen, H. Ye, S. Liu, J. Zhang, C. Wang, X. Han, W. Yang
AAAI Conference on Artificial Intelligence (
AAAI), 2025.
[PDF] [Code] IMAGPose: A Unified Conditional Framework for Pose-Guided Person Generation F. Shen, J. Tang
Neural Information Processing Systems (
NeurIPS), 2024.
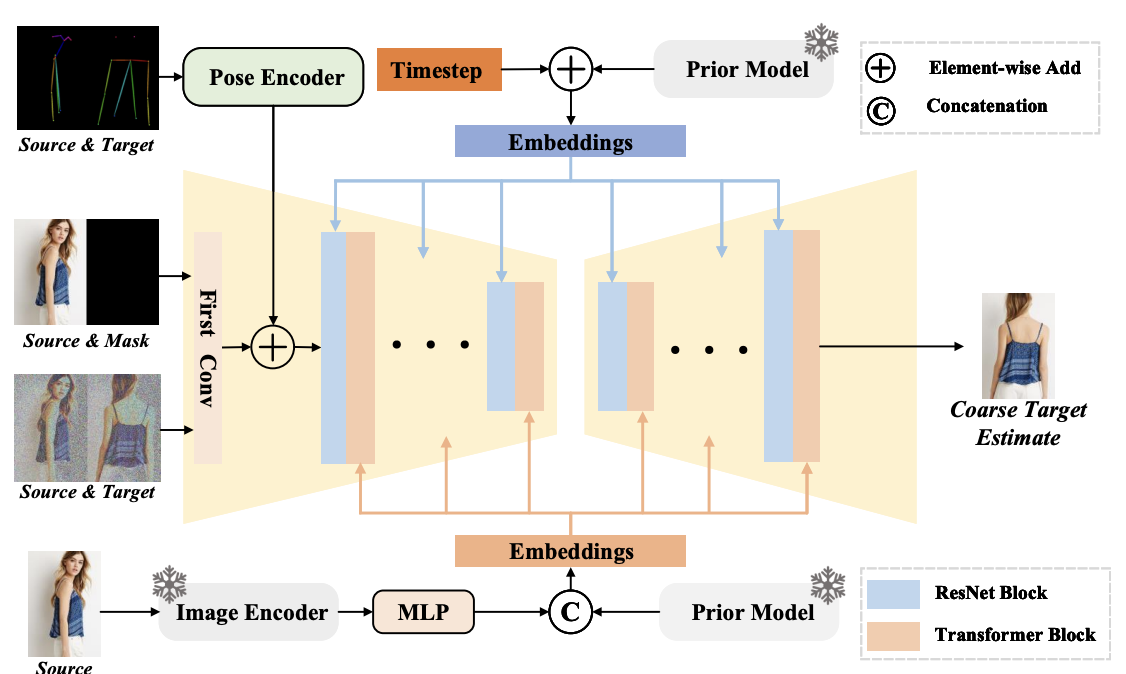
[PDF] [Code] Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models F. Shen, H. Ye, J. Zhang, C. Wang, X. Han, W. Yang
International Conference on Learning Representations (
ICLR), 2024.
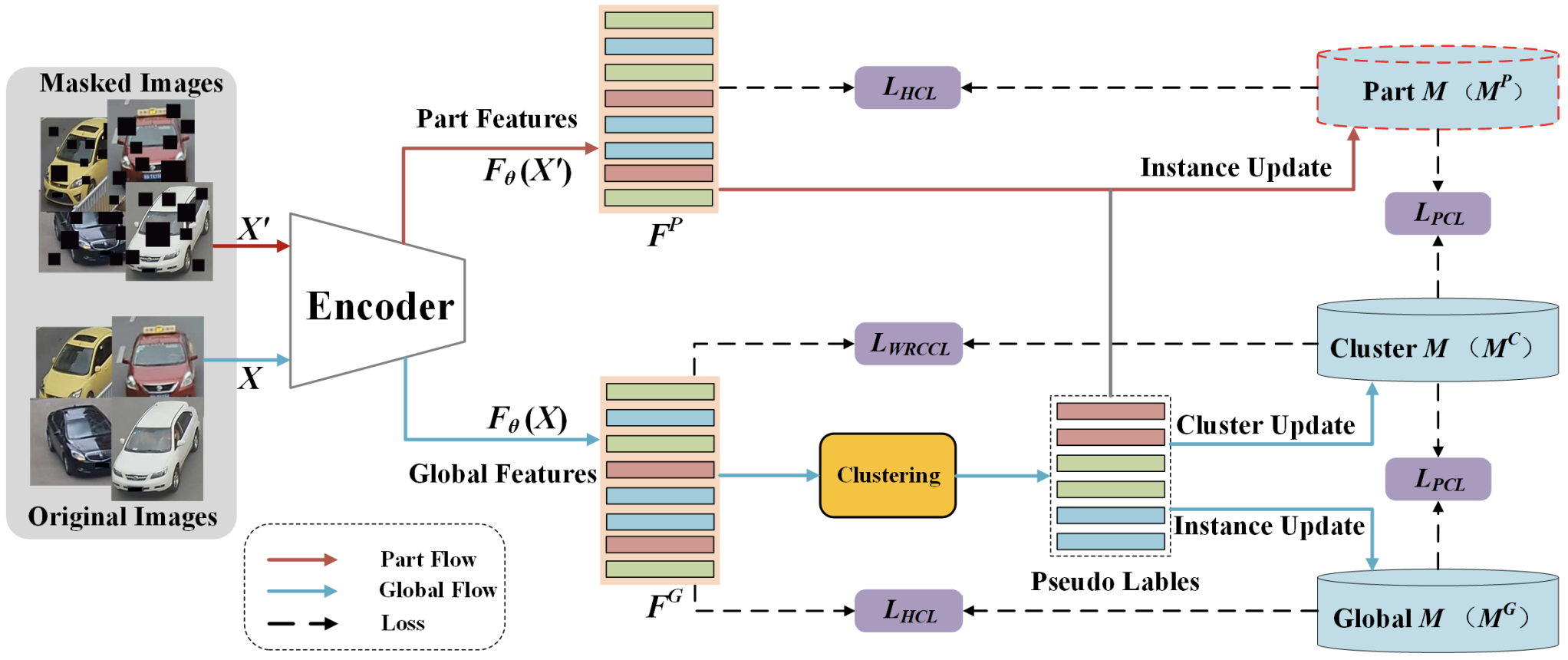
[PDF] [Code] Triplet Contrastive Representation Learning for Unsupervised Vehicle Re-Identification F. Shen, X. Du, L. Zhang, X. Shu, J. Tang
ACM Transactions on Multimedia Computing, Communications and Applications (
ToMM), 2024
.
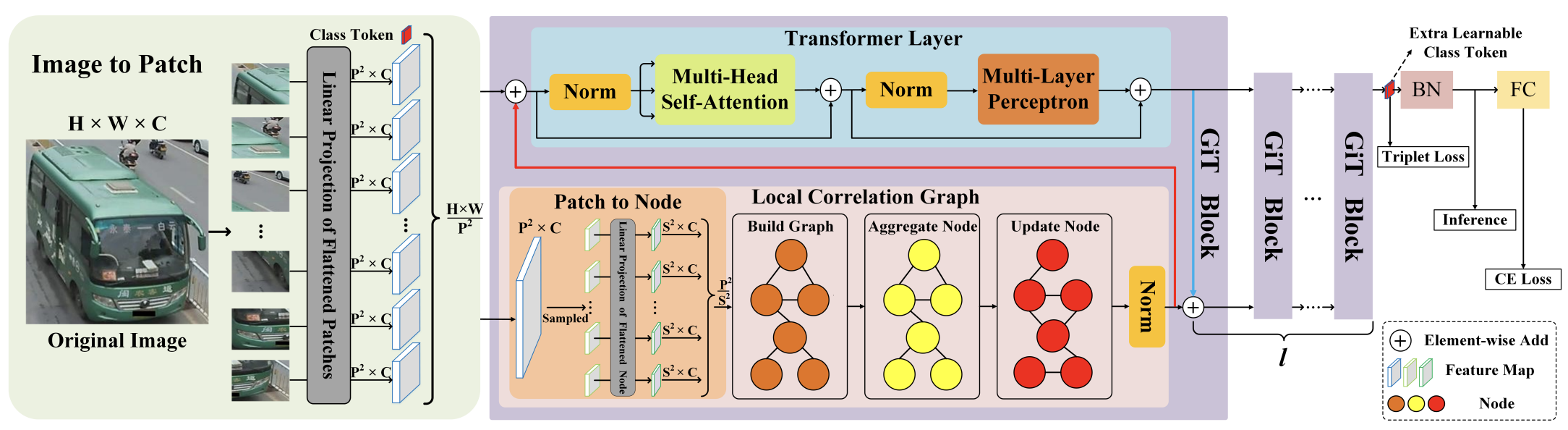
[PDF] [Code] GiT: Graph Interactive Transformer for Vehicle Re-identification F. Shen, Y. Xie, J. Zhu, X. Zhu, H. Zeng
IEEE Transactions on Image Processing (
IEEE TIP), 2023
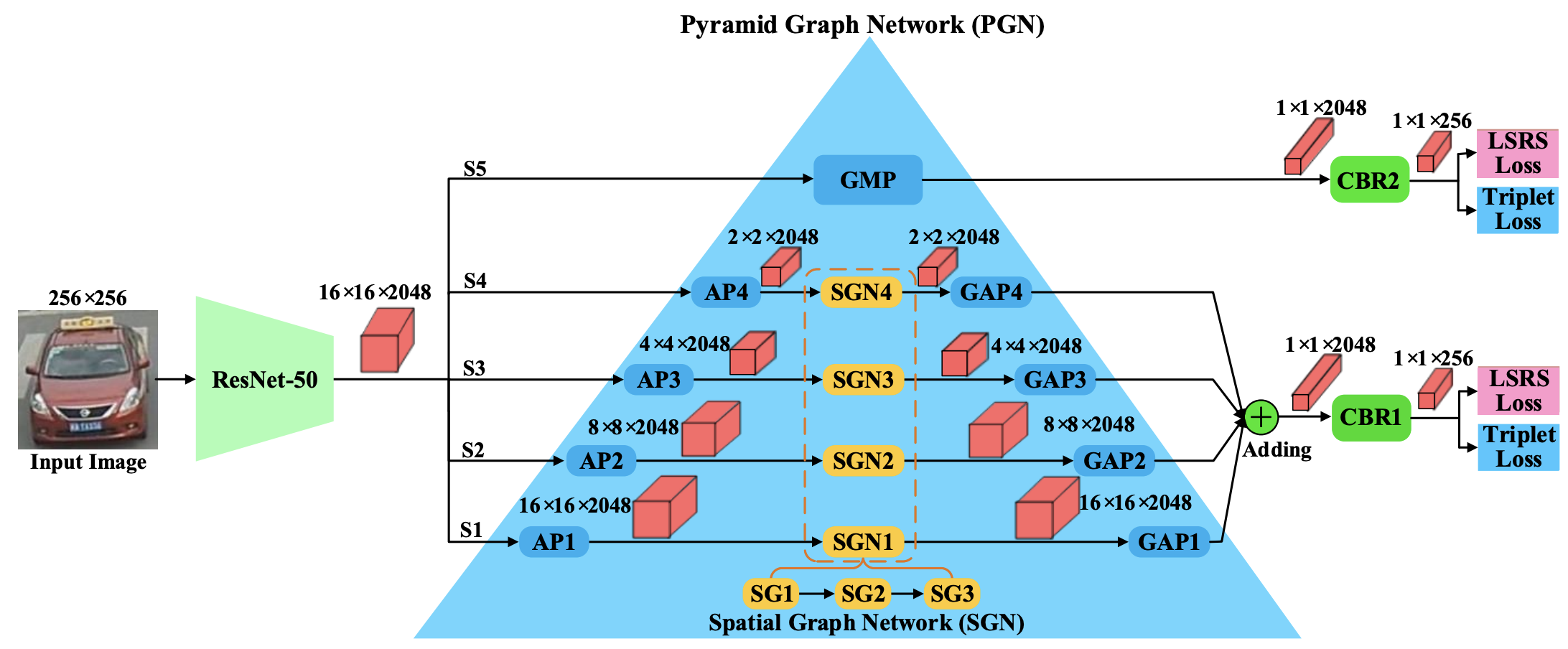
[PDF] [Code] Exploring Spatial Significance via Hybrid Pyramidal Graph Network for Vehicle Re-Identification F. Shen, J. Zhu, X. Zhu, Y. Xie, J. Huang
IEEE Transactions on Intelligent Transportation Systems, (
IEEE TITS), 2023.
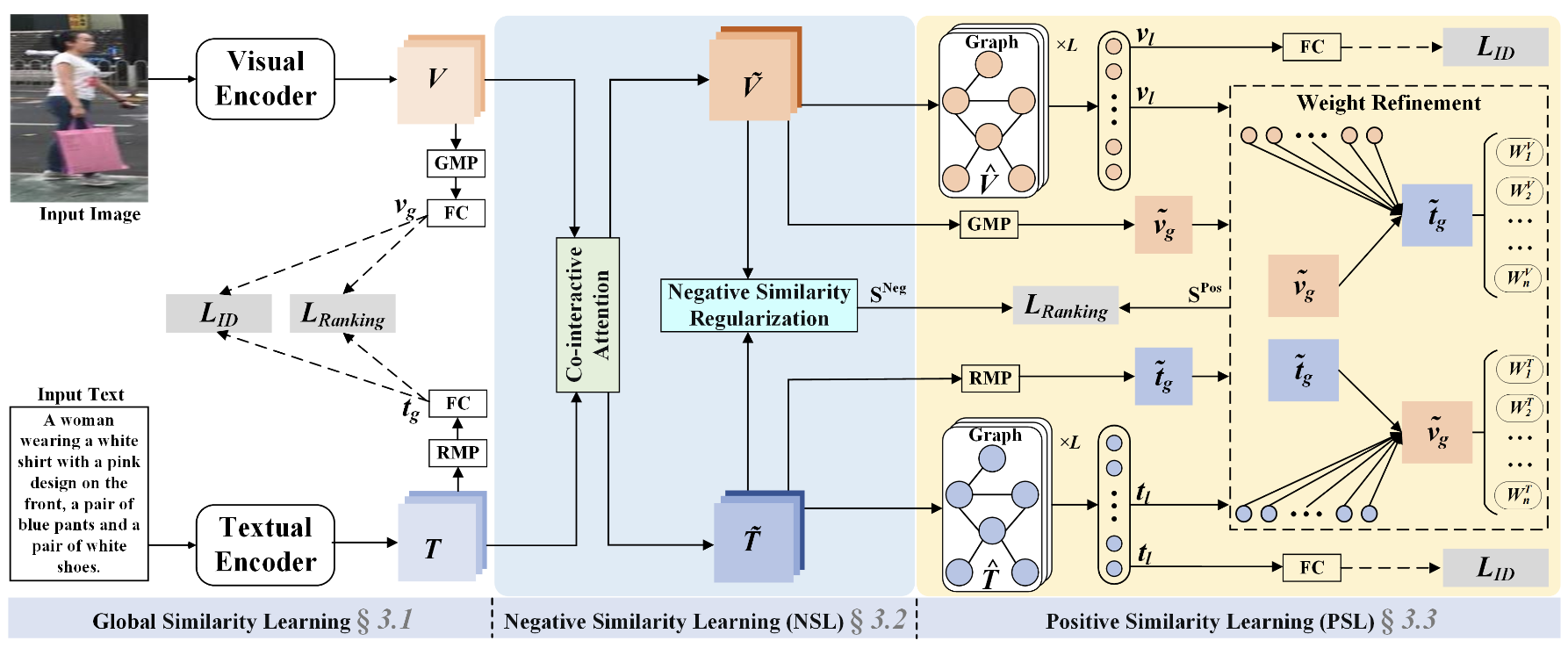
[PDF] [Code] Pedestrian-specific Bipartite-aware Similarity Learning for Text-based Person Retrieval F. Shen, X. Shu, X. Du, J. Tang
ACM International Conference on Multimedia (
ACM MM), 2023.
[PDF] [Code]