ASTRA: Let Arbitrary Subjects Transform in Video Editing

Abstract
While recent advances in generative models have propelled video editing, existing methods primarily focus on single or few subjects and struggle in complex, multi-subject scenarios. Specifically, in dense scenes with heavy occlusions, current approaches often suffer from severe mask boundary entanglement and attention dilution, leading to attribute leakage and temporal instability. To address these critical limitations, we present an arbitrary-subjects training-free retargeting and alignment (ASTRA) framework for video editing that enables an arbitrary number of subjects to transform seamlessly. ASTRA manipulates the appearances of multiple designated subjects while strictly preserving non-target regions, all without requiring any model finetuning or retraining. We achieve this by generating robust multimodal conditioning and precise mask sequences through two core components: a prompt-guided multimodal alignment module and a prior-based mask retargeting module. By leveraging the comprehensive understanding and generation capabilities of large foundation models, these components generate precise multimodal conditions and temporally consistent mask sequences. ASTRA acts as a versatile plug-in that is completely compatible with diverse mask-driven video generation models, significantly enhancing overall editing performance. Extensive experiments on our newly constructed multi-subject benchmark, MSVBench, verify that ASTRA consistently surpasses state-of-the-art methods.
How does it work?
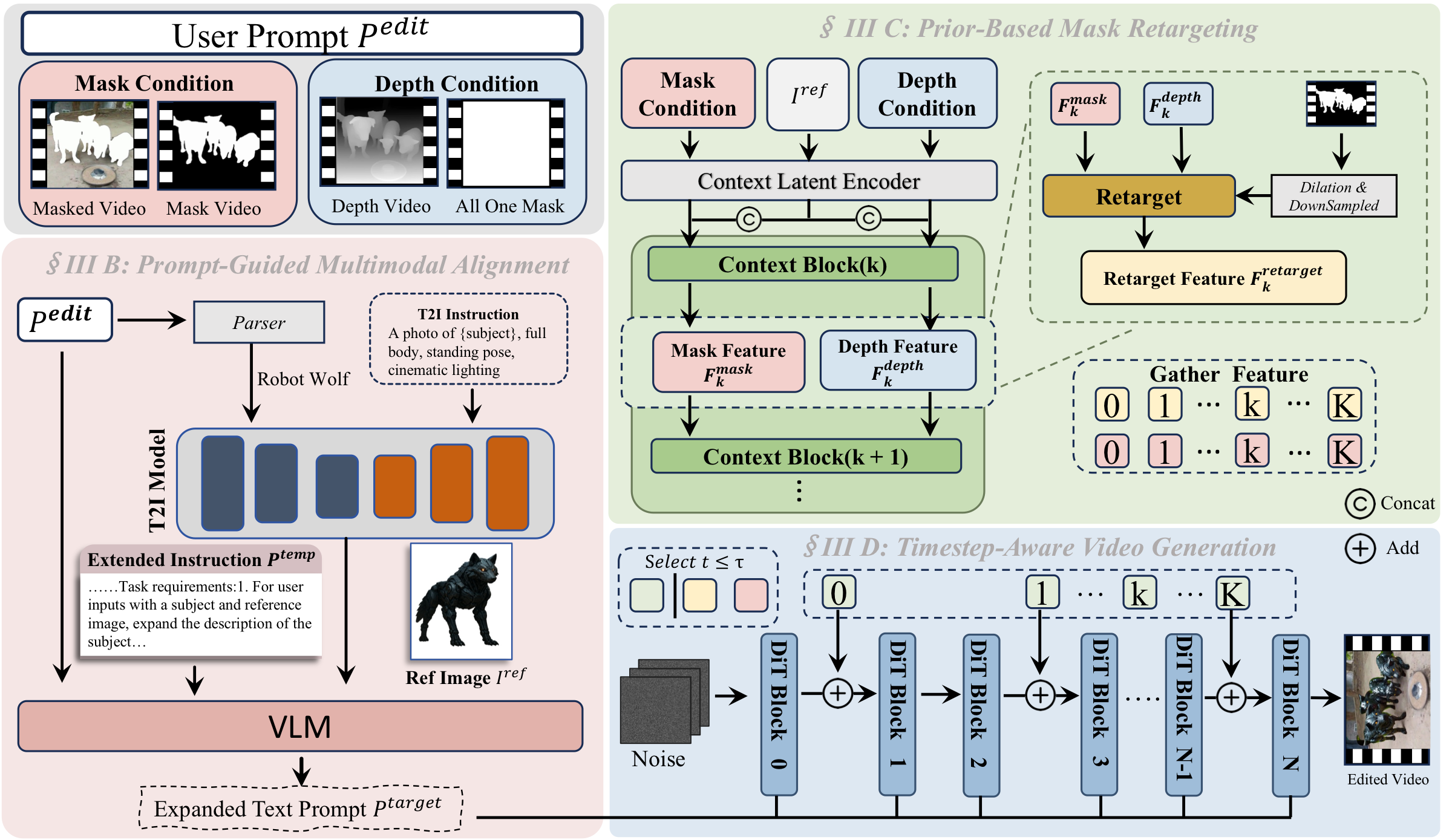
ASTRA is a training-free, plug-and-play framework designed to seamlessly transform an arbitrary number of subjects in video editing. It comprises two synergistic core modules: (i) a Prompt-Guided Multimodal Alignment module that extracts subject-specific tokens from the editing prompt, generates a visual prior via a T2I model, and uses a VLM to produce enriched, visually-grounded textual conditions — effectively resolving attention dilution in crowded multi-subject scenes; and (ii) a Prior-Based Mask Retargeting module that, constrained by depth priors, spatially re-estimates instance boundaries and generates a temporally consistent retargeted mask sequence, significantly reducing mask leakage. Finally, ASTRA adopts a Timestep-Aware Video Generation strategy, applying structural guidance during early denoising steps and reverting to mask-only conditioning in later refinement steps to prevent artifacts while preserving high-frequency details.
Comparison with Other Video Editing Methods
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
Two [Puppies -> Kittens] together on a weighing scale.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
One black sheepdog herding four [Ducks -> Robot Ducks] on green field.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
Four [Female Runners -> Spider-Men] sprint on track.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
Seven [Kabaddi Players -> Gokus] facing each other on a purple mat in stadium lighting.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
[Players -> Spider-Men] on trampolines throwing dodgeballs during an intense match.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
[Relay Runners -> Astronauts] sprinting on track.
Original
FateZero
TokenFlow
VideoPainter
VideoGrain
DMT
ASTRA
[Volleyball Players -> Robots] compete on indoor court with net.
Main Video Results
Three [People -> Super Mario] sitting in car backseat.
Four [People -> Robots] standing on football court.
Four [Hungry Dogs -> Robot Wolves] surrounding a bowl of food outdoors.
A group of [People -> Astronauts] practicing boxing in a fitness studio.
A team of [Men -> Spider-Men] rowing together on a river.
Eight [Hurdlers -> Iron Men] leap mid-race over purple hurdles.
Multi-Scenario Applications
Automn Forest -> Winter Forest
Snowy Forest -> Lunar Surface
The Eiffel Tower -> The Space Needle
Glasses -> Sunglasses
Left -> Ultraman; Right -> Robot
Left -> Gorilla; Right -> Polar Bear
Left -> Lightning McQueen; Right -> Yellow Cartoon Porsche
Two People (arm wrestling) -> Two Supermen
Turn 1: Horse Riders -> Gokus
Turn 2: The two above (Gokus -> Iron-Men)
Add Glasses
Change Face To "Kevin Durant"
Change Face To "LeBron James"
Remove Glasses
Plaid Shirt -> Business Suit
Plaid Shirt -> Hawaiian Shirt
Disclaimer
We make this project openly available to the research community. Most of the datasets and resources involved are either generated by us or obtained under proper licenses. If you believe any material infringes your rights, please contact us, and we will take immediate action to remove or replace the content. Any components derived from third-party models or datasets must strictly follow their original license agreements.
This work is intended to promote academic exploration and innovation in the area of controllable generation. Users are welcome to experiment with the released code and models under the condition that they act in accordance with local regulations and use them responsibly. The authors and contributors disclaim any liability for potential misuse or unintended applications of this tool.
BibTeX
@misc{shen2026astraletarbitrarysubjects,
title={ASTRA: Let Arbitrary Subjects Transform in Video Editing},
author={Fei Shen and Weihao Xu and Rui Yan and Dong Zhang and Xiangbo Shu and Jinhui Tang and Maocheng Zhao},
year={2026},
eprint={2510.01186},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.01186}
}